
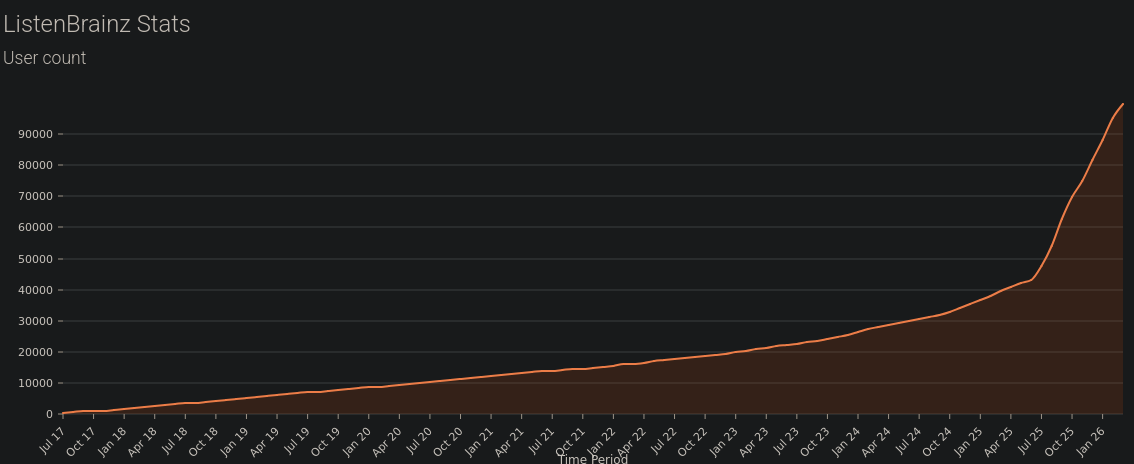
Allow me to spread the word about ListenBrainz , the occasion being that ListenBrainz is about to hit 100.000 users.
ListenBrainz is a FOSS project that aims to crowdsource listening data and release it under an open license. Basically it’s Last.fm but better. Whatever you use to listen to music, you can probably link it up with ListenBrainz. For instance you can connect Spotify, Apple Music, Soundcloud, Last.fm . You can link it up with loads of music players . If you’ve kept track of your what music you’ve listened to up to this point, don’t worry, there are several ways to import them into ListenBrainz.
All ListenBrainz listening data is available for all to use. This means that we don’t need to rely on big companies like Spotify for recommendation algorithms. We can use whatever algorithm suits us best. All sorts of other services could be build to make use of the ListenBrainz data set. The dataset can also help analyze other services’ algorithms, for instance the Fair MusE project uses LB-data and LB-users to investigate the fairness of different music service algorithms.
Obviously ListenBrainz initially suffered from being a comparatively small service, For good recommendations you need loads of data. But it’s growing every day and I feel like the 1 billion listens is an impressive milestone. And ListenBrainz has the advantage of having listening data from several services, Spotify could never recommend you music that’s not on Spotify. ListenBrainz, because it’s open, doesn’t have such inherent blindspots.
I am not working for ListenBrainz in any way, I just really like this project as well as MusicBrainz , and I like to spread the word. I think the aims of the ListenBrainz probably align with some Fediverse-folks. If you don’t care about the service itself, you could still link up to support FOSS music services, not only LB itself, but other services that are, can and will be built using LB’s data. If you use another service to store your own listening data, for instance Last.fm, you could use ListenBrainz as a backup for you data in case the other sevice ever enshittifies. Note: you shouldn’t sign up if you want your listening data to be private, that’s not what LB is for. I care very much about privacy, but in the case of LB I consciously choose to share my music listening data with others for my own benefit.
Curious to hear peoples thought on all this.
P.S. I have posted about LB over a year ago. I don’t intend to spam this service, but i feel like it could be useful for folks on here, and I think most of you folks would support the spreading of FOSS. And LBs usercount rising from 36k january last year to 100k now seemed like a good celebratory occasion to spread the love once more.
This is pretty much the step I need to get back to listening to my own music rather than streaming. Can it plugin to ‘offline’ apps?
apparently it has navidrome support :) navidrome enables you to have your own music library on a device from that you then stream it on your other devices
Can confirm this works with Navidrome. I also have Navidrome updating last.fm as well.
The other way around, and yes.
https://kawaiidango.github.io/pano-scrobbler/ is one example, but most decent Desktop/Mobile applications have some sort of plugin.
Depends on the app.
If it caches the plays and syncs it back to the scrobble service?
Probably possible.
Afaik it’s not possible for Jellyfin.There was a time I used Plex with PlexAmp for music, pretty sure it kept stats
There is a Jellyfin Plugin for this. https://github.com/lyarenei/jellyfin-plugin-listenbrainz
Offline listen history playback is my issue.
I know about the plugin (lol)

(Scrobbled by Spotify and Jellyfin)
Depends. LB supports traditional Lastfm scrobling, so you can use players that scrobbles to Lastfm if you can change the URL
The in-app player is more limited, but a good old Navidrome instance is plenty enough!
So what happens to the data? As far as I can see you’re uploading your music listens to the service and you don’t have a private profile, it’s always public and everything is being provided as a download for everybody. So everybody can get the full amount of my listening history, including Metadata telling them for example when I was awake, listened to sad songs or drinking songs on a thursday night?
Yes, there is not a feature for private profiles. If your listening data is a privacy concern to you it’s better not to use LB.
I felt a bit weird about it at first, but the one thing keeping me tied to Spotify was how useful it was for discovering new music (though even that had been degrading by the time I cancelled it).
If you’re someone who either prefers to listen to music that they already know and love, or someone who enjoys discovering new music through manual effort, then Listenbrainz isn’t for you
However, if you’re currently relying on the recommendations of a service like Spotify, then it’s at least worth considering. For me, I became a lot more at ease with Listenbrainz when I realised that this kind of music recommendation simply isn’t possible without other people’s data — and that part of the “price” for being able to access recommendations built from that data is that my listening history gets added to the pool of listening data used by the recommendation system.
If it’s Spotify’s pool that I’m contributing to, then I feel like I’m getting a pretty bad deal, because they hoard that data like a digital dragon, and then use it to further entrench their monopolistic position in the market. I don’t like that — it makes me feel complicit in the grossness.
Whereas with Listenbrainz, I’m contributing to a data commons of sorts. Listenbrainz’s recommendation algorithm has gotten so much better in the couple of years that I’ve been using it, and that wouldn’t be possible without a growing pool of data. Independent researchers and developers are able to benefit from it, and the more people we have making stuff in this space, the more we chip away at Spotify’s power.
Like I said, having my data be so public does make me feel a tad uneasy, but with data like this, it tends to only be valuable in bulk (meaning the system doesn’t care about any individual’s sad drinking songs), or hypothetically, to individuals who are excessively concerned with another individual (such as stalkers, I guess). However, that last point doesn’t concern me, because I made my Listenbrainz account under a username that’s unconnected to any of my others, and my profile shows no indication of who I am on Spotify.
I’m sure that someone dedicated and skilled enough could retrieve my Spotify account name from the system, because I linked my account way back when I did have Spotify, but I trust Listenbrainz with my data a hell of a lot more than I do Spotify. Spotify definitely have way more money to hire cybersecurity folk to prevent exfiltration of user data, but they’re so opaque that even if there were a breach, I wouldn’t trust them to tell me. I’ve been following Listenbrainz’s development for a while, and they’re pretty cautious and transparent with how they go about things.
To be clear, I’m not formally affiliated with Listenbrainz in any way. I have contributed to improving documentation a few times (because that’s usually the best way I can support open source projects, as a mediocre programmer), but that stems from the same thing that made me write this comment: I just really like what they’re trying to do, and I think the world would be a little better if more people joined it. (also, I am just a huge nerd for metadata schema, and the affiliated musicbrainz project has so much cool stuff for me to learn about)
Yeah, I think one issue is how this aggregate data is being provided for download. Is it really “this user has listened to this song on this day at this minute”, or is it kind of an aggregate data like “users who listen to Metallica also listen to Pantera” and “the most listened song for Taylor Swift is shake it off”?
Yes I think it is like you describe.
Here is someone from MetaBrainz explaining why.
Such a great service.
Both it and musicbrainz.Used Last.fm for like 3 months before finding out about ListenBrainz and making the switch. Truly amazing app, love all of their services (Picard my goat) and I’m happy to hear more people are joining!
I wish the social aspect was a bit more active though, I always follow people with similar taste but I never get a follow back (and the accounts always have 0 people they follow). Also I never see pinned songs and such :(
I agree on the social aspect lacking a bit. But who knows, ListenBrainz got better and better over the past years, perhaps with more users there will be more demand for social functionalities aswell, and perhaps they’ll be implemented in the future. LB was very rudimentary when I signed up, it’s nice seeing it grow and improve.
Listenbrqinz seems to keep prioritizing the discovery aspect rather than the stats
Yeah, it’s pretty low on the social side of things. However, having watched the massive progress the project has made over the last few years makes me hopeful that it’ll continue to improve. They seem to be quite smart about how they go about developing new features, which is wise for an open source project. It’s been pretty cool to watch how good their recommendation algorithm has been getting though, compared to when I first joined
Hear hear! I love me the brainz projects. Their player is a bit buggy still but so so good to avoid being locked in
I’m still bummed the AcousticBrainz project folded - I developed a decent DJ algorithm off of that data and would love to take it further, but running my own Essentia analyses ups the bar considerably.
Got the app on my phone and the player on my PC is linked and donated $5. Listen brainz is a treasure that will pay dividends to open source for years to come.
Yessss! I am so jazzed to see other people in this thread who love Listenbrainz as much as I do.
I will always love it because it was my first ever contribution to open source software. It was only documentation, because I’m a mediocre programmer, but documentation is a big deal for projects like these.
What I really liked about contributing is that I felt a real sense of contributing to something bigger than myself. I mean, I feel that with the fact that my listening data gets added to the pool itself, but I felt it even more so when helping with the documentation.
It was only something small, but I liked the idea that I was helping future tinkerers experience a little less frustration than I felt when I struggled with the outdated documentation. It made me happy to think that I was facilitating more people to tinker. I may only be a mediocre programmer, but that just means I am well placed to help pave the way for people more skilled than I am. This is the kind of project that I want to exist in the world, and so helping to support it genuinely makes me feel a little more hopeful in the face of this increasingly enshittified world
I have been using Last.fm for almost 20 years. Still using it because I already know it well and it works.
I hadn’t done my homework yet on ListenBrainz, despite using Picard for a couple years now.
Welp, your words convinced me that I should make the switch. Thank you for your post!
Can someone explain to a Gen x guy what “listening data” gets me? I’ve been living off a folder of mp3s for 30 years. Does this use my music? Does this get it from the Internet somewhere? How is it different from asking Alexa to play music for me? Thanks.
I’ve been living off a folder of mp3s for 30 years.
Same here. I love that shit. My mood is the algorithm. I still occasionally get new stuff, but from other sources I happen to see or hear, like a Netflix show that has it in the background or a musician’s personal recommendation in an interview, and I go look it up manually. But even if I never got anything new, I already have more music than I could easily listen to in a lifetime that I already know I liked at least once.
I’ve tried streaming sources, but it never hits right. This way, where I am specifically picking the artist or album, it’s always right, always fresh, and I’m always listening to something I want to hear.
where I am specifically picking the artist or album, it’s always right
That’s a remarkable level of effort, these days. Yes, I know, it’s trivial compared to pulling vinyl from the sleeve and flipping it every 20 minutes the way I used to before 1985, but… I prefer to put in my music effort with focus, and let a mix algorithm surprise me when I’m not in “music picking mode.” To me, it’s much more enjoyable to hear a song I like that I wasn’t expecting than it is to think about it, navigate the list of thousands to find my pick, and then hear the thing I was thinking of.
It’s all good. I think it has a lot more to do with accommodating one’s own brain, and how we individually categorize and enjoy our listening, than with specifics of music like genre/artist/album/track.
For myself, I almost always have some tune or another out of nowhere running through my head, so when I choose something to listen to, I am either picking with or against what’s already playing. So if I tune in to the music that’s already playing, I can see associated choices that are the same, similar, or completely unrelated on a superficial level, but my brain has linked them all somehow. Any of those choices, if I put them on, will satisfy because my brain is already playing one and mentally I’m already there.
I think the reasons algorithms never work for me is because no one could ever follow that, much less predict it. Even I can’t. Instead I’ve learned to simply accommodate it.
so when I choose something to listen to, I am either picking with or against what’s already playing.
AcousticBrainz has (had?) a bunch of dimensional measures of various qualities of a song. How I used it was to first define a set of maybe 4 to 8 songs to “set the mood” and then pick a list of a few hundred songs that were “closest to” those songs in all the AB dimensional measures, pre-filtering out artists and songs recently played. Then - the final step was to sort the remaining candidates by their similarity to the songs most recently played. It was still random within that list, but a weighted random with the most similar (by AB measurements) songs most likely to be queued up next.
I have yet to find an algorithm that has figured out what I like about music. So I curate my own collection. Only way it works for me.
What works for me is to have a pool of thousands of “songs I like” - but then you’ve got the mood problem: Metallica or Sarah McLaughlin? That’s what AcousticBrainz was good at: picking through my collection for similar songs and playing that “mood” from the pool of songs I’ve already indicated I like by including them in the available list to choose from.
Where it excelled was at finding the outliers, like the relatively quiet Metallica song that fits with the current set.
I’ve been using LastFM for nearly two decades now. First of all, having personal listening statistics is kind of fun. It might be not for everybody, but it’s nice to see which albums are your most played over a year or what you listened to back in 2015, how your favorite artists changed, which album really vibed with you and so on.
Second, you can get really good recommendations for new music when you have a larger user base and are running into a smaller genres. So just like Amazon’s and people who bought this product also bought that product for music. So people who listen to Britney Spiels also like to listen to Christina Aguilera. That might be obvious for you, but it’s totally interesting if you go down some of these genres and if you want to explore them.
And on a broader scale, listening data is quite valuable to create a good music service. So if somebody never heard of a band called Deep Purple and wants to change that, there might be this one song everybody knows from Deep Purple. And this is, of course, the most popular, but how do you find out that this is the most popular? So if you have your own Jellyfin installation, you load in several albums of Deep Purple, but you need some data source to tell you that ‘smoke on the water’ is that famous song from Deep Purple that everybody’s listening to.
I love listening stats, I just don’t need to share them, and for that I have Navidrome. I use subsonic clients and a Navidrome server for my Bandcamp purchased. I get the stats and privacy too…
It depends on your preferences, but myself I just like knowing what I listen to a lot and send my monthly cover art collage to brag about my blorbos

The player / radio are nice, but I personally created my own radio generator based on my data
It’s a scrobbling service. You send your listening data to it so that you can see your listening habits and share them with other people (your top songs, which countries the artists you listen to are from, etc.). It’s just interesting data that some people like to collect, but if you only throw on your mp3s and don’t care about that, then you probably won’t find much use in setting it up.
Edit: to clarify what “listening data” means here, it just means the metadata of the music you play. Song name, artist, album. Nothing fancy. I think it also supports marking songs as favorites.
Is there no way of connecting it to Qobuz? I can’t seem to find it.
If you listen on Android, you can use PanoScrobbler. I suspect their are ways on other platforms as well
I used to use the ListenBrainz app to scrobble from YT music until it had a stroke around December, so now I use Pano Scrobbler on Android. You can tell it what apps to monitor/scrobble from.
I found a web scrobbler extension that seems to be pretty popular on github that’s available for like every browser and supports multiple services. But I haven’t tried this before yet.
Unrelated Selfhosting Note
I also selfhost a Navidrome, which can scrobble automatically on both web or via Andriod clients like Tempus once you link your account in the server settings. I love my Navidrome + Tempus combo ❤️
That’s awesome! I’ll check it out, thanks!
Been an LB user for more than 2 years now, and it’s been my nerd snipping since then. The metadata is a joy to work with, and it’s quite easy to script things.
It does have that “brand new app” smell to it, but that means you get to experience seeing a long awaited feature finally getting done.
I use Koito as a selfhosted version of this. I use the ListenBrainz plugin to send my Jellyfin listening data to Koito, which has a setting to forward that data to ListenBrainz so I can have a backup and contribute to the ListenBrainz project. It’s pretty cool!
Koito is fantastic. I’m so ready to dump Maloja but won’t yet until Koito gets an official stable build. Multi-scrobbler is a lifesaver.
I like using symfonium for my music player, maybe it could be integrated.
I use Symfonium to play my Jellyfin library, and Jellyfin has a plugin for ListenBrainz integration. So depending on your setup, there already is integration!
If you use Navidrome, you can connect it to LB.
Thanks for the tip, will check it out. The only things that bugs me it that there source code is only on Microsoft Github service, just self-host forgejo like sane FOSS projects do
How do they handle fake data submissions? Ignore and let consumers figure that out?
I already use MusicBrainz Picard to scan and sort my music files.















