

I recently discovered that some popular federated instances have been using LLM-assisted moderation tooling that evaluates whether someone has said something bannable. They do this by running a script/app that sends the user’s comment history to OpenAI with the question “analyze this content for evidence of specific political ideology sentiment. Also identify any related political ideology tropes“. (The italic bits are where I’ve redacted the ideology they’re seeking).
OpenAI’s LLM (they’re using GPT-5.3-mini) then responds with something like:
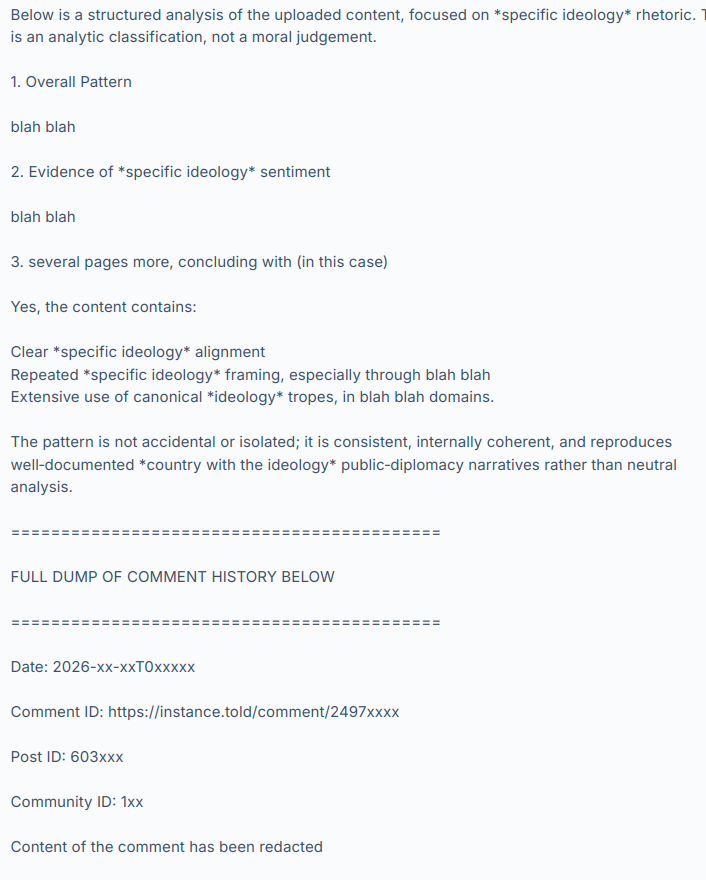
and so on, hundreds of comments.
I have not named the instances or people involved, to give them time to consider the results of this discussion, make any corrective changes they want and disclose their practices at their own pace and in their own way. I have also redacted the evidence to avoid personal attacks and dogpiling. Let’s focus on the system, not the individuals involved. Today these instances and people are using it and maybe we’re ok with that because it’s being used by groups we agree with but what if people we strongly disagree with used it on their instances tomorrow?
The use and existence of this tooling raises a lot of other questions too.
What are the risks? Fedi moderators are often unsupervised, untrained volunteers and these are powerful tools.
What safeguards do we need?
Would asking a LLM “please evaluate this person’s political opinions” give different results than “find evidence we can use to ban them” (as used in the cases I’ve seen)?
What are our transparency expectations?
Is this acceptable and normal?
Should this tooling be disclosed? (it was not – should it have been?)
If you were given a choice, would you have opted out of it?
Can we opt out?
Are there GDPR implications? Privacy implications? Should these tools be described in a privacy policy?
Are private messages being scanned and sent to OpenAI?
How long should these assessments be retained and can we request to see it, or ask for it to be deleted?
Once the user’s comments are sent to OpenAI, is it used to train their models?
What will the effect be on our discourse and culture if people know they are being politically profiled?
Where are the lines between normal moderation assistance tools, political profiling and opaque 3rd-party data processing?
I hope that by chewing over these questions we can begin to establish some norms and expectations around this technology. The fediverse doesn’t have any centralized enforcement so we need discussions like this to develop an awareness of what people want in terms of disclosure, privacy, consent and acceptable use. Then people can make choices about which instances they join and which ones they interact with remotely.
And of course there are the other issues with LLMs relating to environmental sustainability, erosion of worker’s rights, increasing the cost of living and on and on. I can’t see PieFed adding any functionality like this anytime soon. But it’s happening out there anyway so now we need to talk about it.
What do you make of this?
It’s at least one admin, we don’t know how widely it’s used. It does have the logo of a group of 3 instances (Fediverse Anarchist Flotilla), so it seems to be made to be used by many people in an ongoing way.
More details at: https://piefed.social/c/[email protected]/p/2035379/proof-of-ai-assisted-political-profiling-by-unruffled-lemmy-dbzer0-com
Thanks. “For evidence log see https://s.faf-pb.xyz/lXxek” feels wrong, but it seems to prove your claim that some admins/mods are farming moderation out to LLMs. Unfortunately that link doesn’t go anywhere (for me), but I believe your claim that this is a concerted effort (as in, someone is coding a tool to do LLM modding).
Sorry for how that whole discussion is going for you. I think you make important, valid points but made a few “tactical” mistakes (I’m sure someone will be along shortly to tell me they’re much worse than tactical) and are now getting shouted & voted down by people who think like programmers: precise, technical, no room for ethical gradients. I have seen this sort of behavior many times before…
This claim is wrong
https://lemmy.dbzer0.com/comment/25880065
Also the LLM was running locally nothing got sent to OpenAI
quite frankly it’s shameful to leave this slanderous post up without even linking to the accused parties statement.
They took the link down.
I have a copy - https://join.piefed.social/wp-content/uploads/2026/05/evidence-llm-used-for-banning.txt
Lying little shit “the host is experiencing an error” is different from “they took the link down”. One is a server issue, i. e. The entire site is inaccessible, the other implies malice.
Also the modlog clearly states “expires in 30 days” meaning it will eventually be gone regardless.
Also they aren’t “farming moderation out” you know this and still don’t correct it https://lem.lemmy.blahaj.zone/post/42212552/20361800
Has he always been like this? It reminds me of goat, pj, and cm002’s shameless greasiness.
Being a lying little shit is all @[email protected] has to go on.
Hi,
@[email protected]
I am requesting you to remove my personal data from the mod log on Lemmy.world. In the email I sent to you, I included the link to the content I wish to be deleted. Reply to me here or throughout email.
@[email protected] Hi, Can you take a look at my email? I am requesting you to remove my personal data from the mods log on Lemmy.world.
I.e. “I just saw a modlog entry, jumped to conclusions, didn’t ask for clarification, didn’t speak to anyone from that instance, jumped straight into making a drama post”
Correction, three drama posts.
Nah. I discussed it with Unruffled days ago. Here’s a screenshot from Matrix in the Threadiverse Admins room:
In which I stated there was no automated ban process, no less. That is perfectly consistent with what I have said all along, and exactly the opposite of what you later claimed was going on. Honestly, this just makes things look worse in terms of your public accusations.
@[email protected]