
Meta has released and open-sourced Llama 3.1 in three different sizes: 8B, 70B, and 405B
This new Llama iteration and update brings state-of-the-art performance to open-source ecosystems.
If you’ve had a chance to use Llama 3.1 in any of its variants - let us know how you like it and what you’re using it for in the comments below!
Llama 3.1 Megathread
For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental evaluation suggests that our flagship model is competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet. Additionally, our smaller models are competitive with closed and open models that have a similar number of parameters.
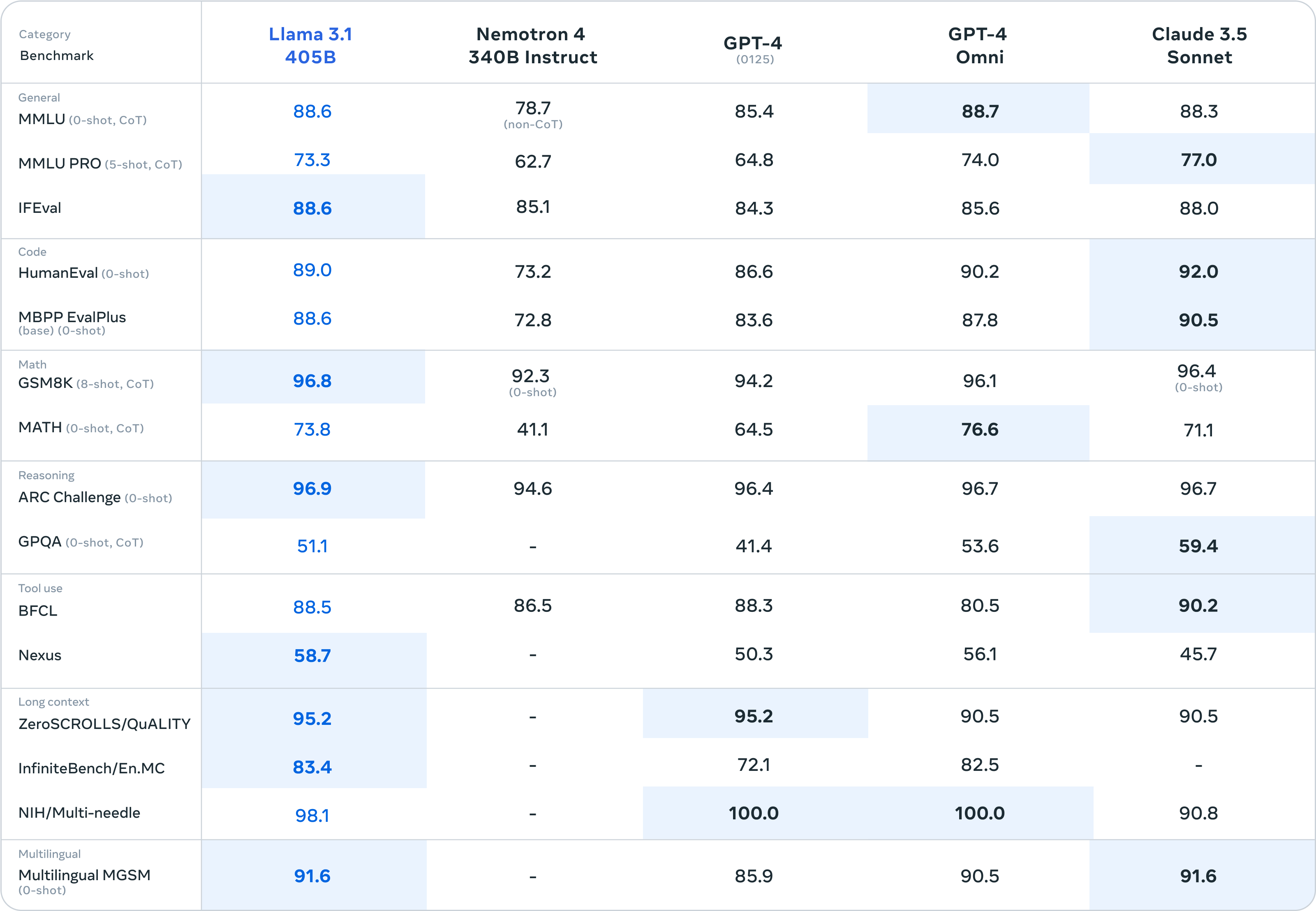
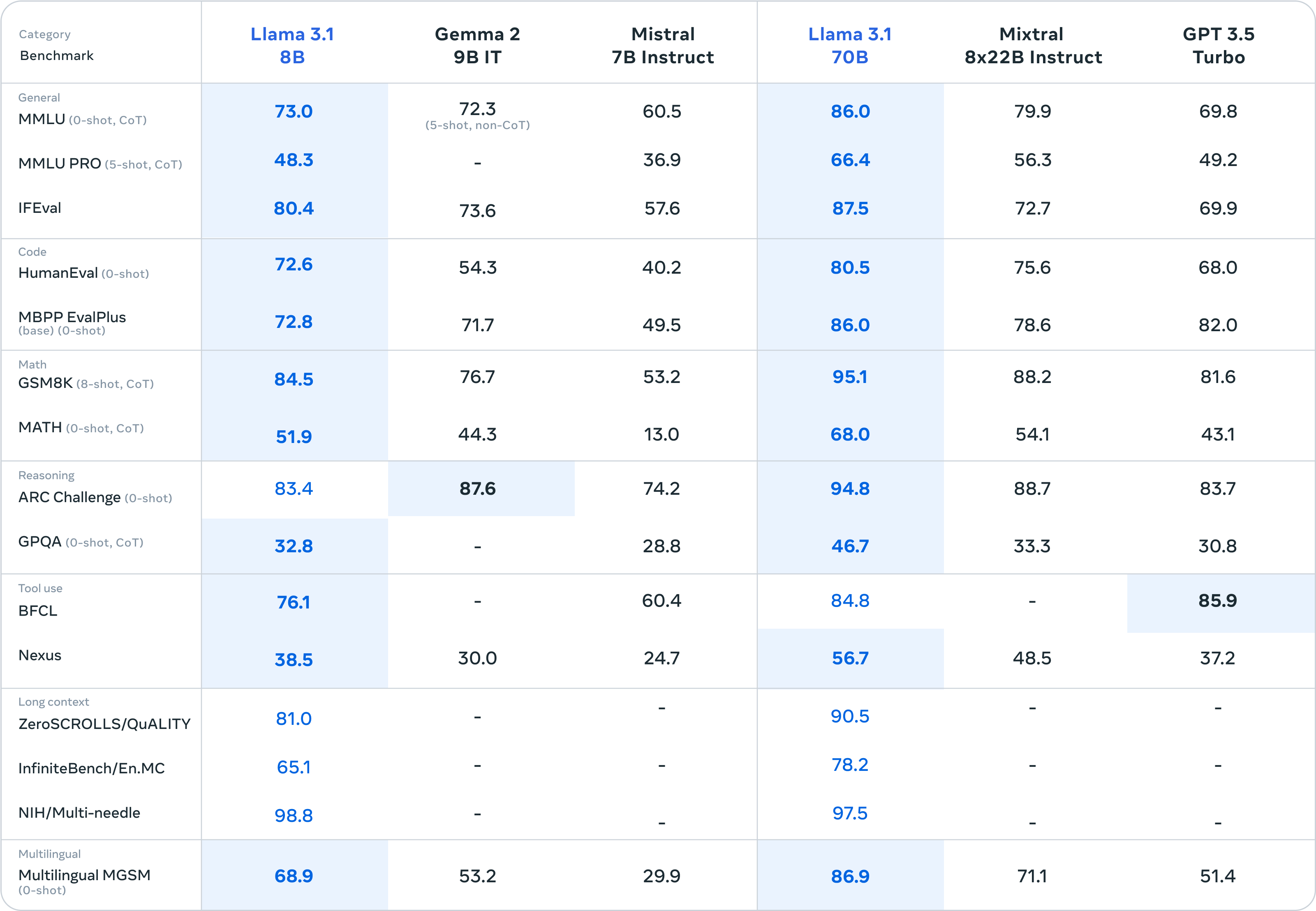
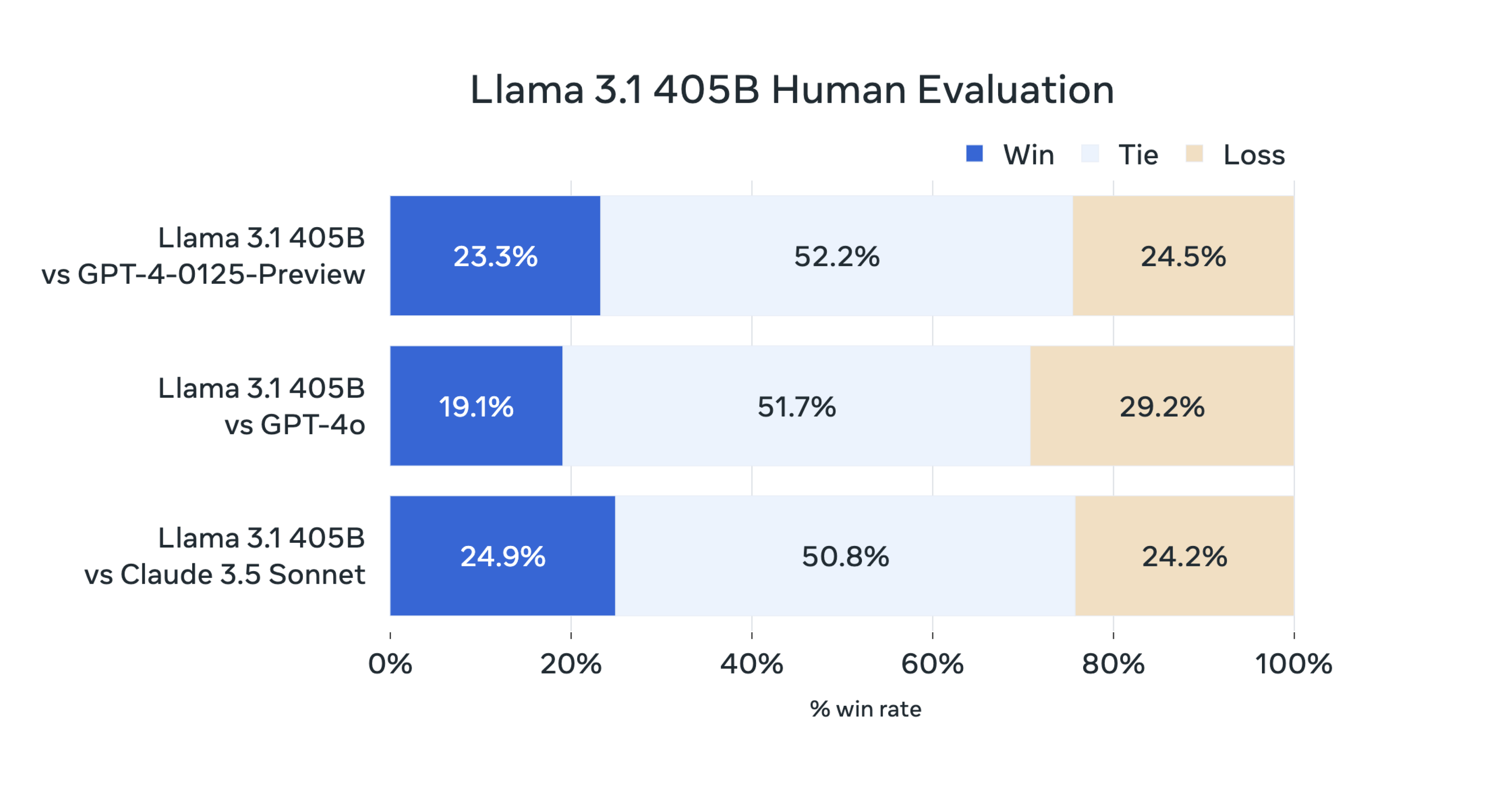
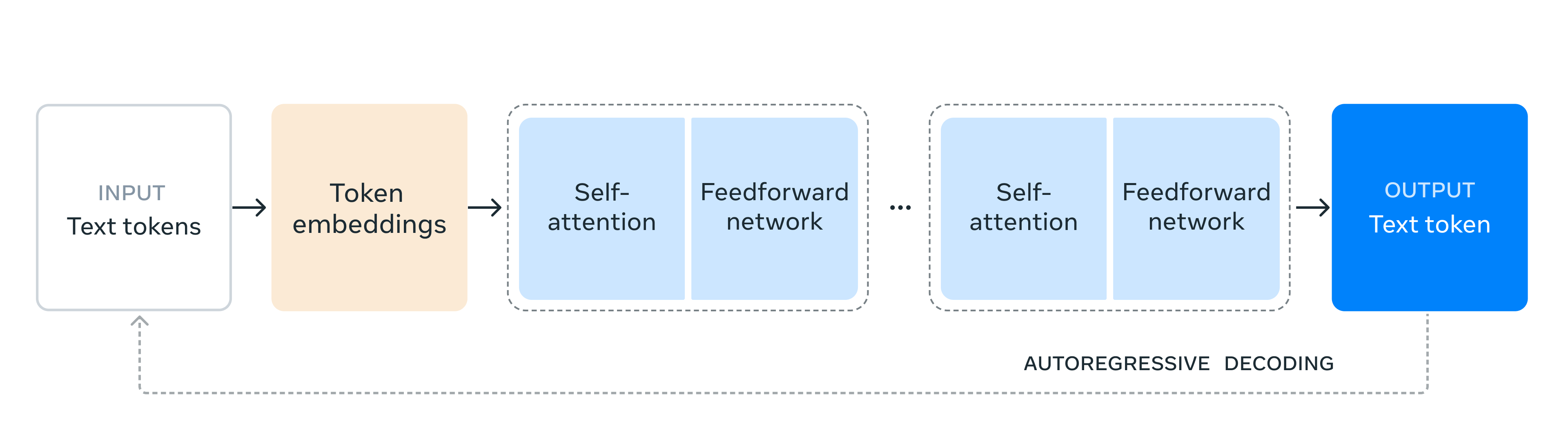
As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.
Official Meta News & Documentation
- https://llama.meta.com/
- https://ai.meta.com/blog/meta-llama-3-1/
- https://llama.meta.com/docs/overview
- https://llama.meta.com/llama-downloads/
- https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md
See also: The Llama 3 Herd of Models paper here:
HuggingFace Download Links
8B
Meta-Llama-3.1-8B
Meta-Llama-3.1-8B-Instruct
Llama-Guard-3-8B
Llama-Guard-3-8B-INT8
70B
Meta-Llama-3.1-70B
Meta-Llama-3.1-70B-Instruct
405B
Meta-Llama-3.1-405B-FP8
Meta-Llama-3.1-405B-Instruct-FP8
Meta-Llama-3.1-405B
Meta-Llama-3.1-405B-Instruct
Getting the models
You can download the models directly from Meta or one of our download partners: Hugging Face or Kaggle.
Alternatively, you can work with ecosystem partners to access the models through the services they provide. This approach can be especially useful if you want to work with the Llama 3.1 405B model.
Note: Llama 3.1 405B requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing.
Learn more at:
Running the models
Linux
Windows
Mac
Cloud
More guides and resources
How-to Fine-tune Llama 3.1 models
Quantizing Llama 3.1 models
Prompting Llama 3.1 models
Llama 3.1 recipes
YouTube media
Rowan Cheung - Mark Zuckerberg on Llama 3.1, Open Source, AI Agents, Safety, and more
Matthew Berman - BREAKING: LLaMA 405b is here! Open-source is now FRONTIER!
Wes Roth - Zuckerberg goes SCORCHED EARTH… Llama 3.1 BREAKS the “AGI Industry”*
1littlecoder - How to DOWNLOAD Llama 3.1 LLMs
Bloomberg - Inside Mark Zuckerberg’s AI Era | The Circuit
You must log in or register to comment.
super exciting, but in a way i have kind of “lost interest” in frontier models, since the resources needed to run them is beyond what most people have access to. i mostly see the future in smaller models (like 3.1 8B for example), anyone else share this feeling?
also unrelated but, i was previously librecat on here (my last instance stopped working)
Agreed - 8b has enough magic to hold a conversation and do small tasks, such as breaking up a large task or picking out key details, which can then be fed into more small models (maybe even more narrowly fine-tuned ones)
180b isn’t enough to replace all the other pieces of a system that you need for autonomous action or memory
I think 8b models are enough to make AGI possible if we stack them just right. They’re enough to fill in most of the gaps to make practical things too, and they’re not that far off for everything else
I tried downloading and running the 405B locally through LM-Studio. Got an error message saying invalid tokenizer. Then tried it with ollama. That didn’t work either. Going to try the 70B tomorrow.
Not sure it’s possible to run the larger ones on a Mac laptop.
There’s apparently some tuning that needs to be done in Llama.cpp (which LM Studio uses to run) so Llama 3.1 can work properly: https://github.com/ggerganov/llama.cpp/issues/8650
Thank you. Looks like I’m not alone and people are doing more detailed testing. I’ll just wait till the dust settles.
In strongly recommend going with 8B first. You might be surprised how good this small model is.
Does anyone know how the base (/foundation) model works? Up until now they always released one instruction tuned variant and one base model. Is it the same for the 405B model? And if yes, does that base model refuse to do things? Because I read some people claiming the new Llama 3.1 is more restricted than the versions before. But this shouldn’t apply to a base model. It’s just the instruct-tuned variants that are aligned to some “guardrails”. I’m confused. Do people use the wrong model? Or has something changed?
IMO guardrails have been irrelevant for “local” models forever since a little prompt engineering or manipulation blows them away,.
In theory the base model should be less “censored,” but really its just for raw completion/continuation and further finetuning.
But it’s super annoying when doing storywriting or using it as an agent. And then you have to do detection and extra handling of refusals, circumvent them and write extra prompts. And I think I read some paper that jailbreaking and removing “censorship” tends to make the models a bit stupider. I think in general it’s way more clever to take a model without guardrails and fine-tune it, than to put them in place and then remove them again, degrade the model in the process and also make your life harder. A base model should be entirely without any censorship. (It’s a base model though. It obviously won’t follow instructions or answer questions… It’s the basis for the community to take and fine-tune, aligned with our vision of baked-in ethics or the lack thereof.)
Yeah, well, I have been using base models and a few instruct tunes for a bit and haven’t even gotten refusals, as long as there as enough existing context.
Sure. Depends entirely on which instruct tuned model you choose. The official one from Meta has guardrails in place. A community tuned one (like Fimbulvetr, Stheno, …) generally build on the base variant and comes without any guardrails. There are exceptions to the rule, some extend the other variant or some other model. I think Mistral also has censorship. And the big ones like ChatGPT are heavily censored. This also makes it creep into other models if they heavily rely on synthetic data from ChatGPT without mitigating for that. I’m not sure which model you took.
I really dislike being lectured by ChatGPT, being forced to have an argument with my computer before it does the task I hand out. It’s not a big deal for some tasks like enhancing my mails, but I’m trying to get a bit more creative with AI. And things I really had difficulties with were writing a detective / murder mystery story, writing (lewd) fan fiction and songtexts which I want to generate for Suno. I just avoid all the “censored” models and ChatGPT, because it usually goes on a long tangent and lectures me about murder and why it’s wrong and how you have to consider both sides of a story. Plain refuses to talk about some stuff and won’t touch adult topics. Even if I tell it 10 times that it’s pretty common to write songs or stories about such things.
I’ve tried several “jailbreaks” and maybe I’m too late to the game, because I found dozens of prompts for ChatGPT and not even one worked for me. (And these are only some examples. I think these tools are also not supposed to give you medical advice, be a lawyer … and I regularly get something trigger the safety mechanisms. But I’m a responsible adult and want to be treated like one.)So I just use the Llama models. And I like their tone and way of speaking to me way better. Hence my question if there’s a base model available and I can expect some good community fine-tunes in the future, entirely without refusals and long lectures about ethics. And ideally I’d like to not have it censored and the un-censired and use a degraded version, but an unrestricted one from the community like I used before. (Btw also Meta seems to have improved their approach. Also the newer “censored” versions don’t outright refuse. They’re very polite and try to offer you an alternative. But sadly I want what I asked for and not something else.)
I think I can answer my question now. There wasn’t much first-hand information available when I first asked. But it seems they have a base variant and an instruct tuned variant available. I’m still not sure if they did something to it, but if they stick to what the term “base model” meant, it should be what I’m looking for.
Kind of petty from Zuck not to roll it out in Europe due to the digital services act… But also kind of weird since it’s open source? What’s stopping anyone from downloading the model and creating a web ui for Europe users?


